

Librarians: please unlink or nofollow sites you don’t want to lend your authority to. Continue reading “Unlink hate – libraries, remove those links to racist websites”
putting the rarin back in librarian since 1999
Librarians: please unlink or nofollow sites you don’t want to lend your authority to. Continue reading “Unlink hate – libraries, remove those links to racist websites”
I wrote an article for Computers in Libraries last week about the PicPedant account on twitter and the odd preponderance/problem of unsourced images flying around the internet. This is just a true thing about how the internet works and people have been misattributing things since forever. However, there’s a new wrinkle in this process where the combination of popular blogs/twitter accounts along with some of the “secret sauce” aspects to how Google works creates this odd phenomenon which can actually amplify misinformation more than you might expect. Here’s my example.

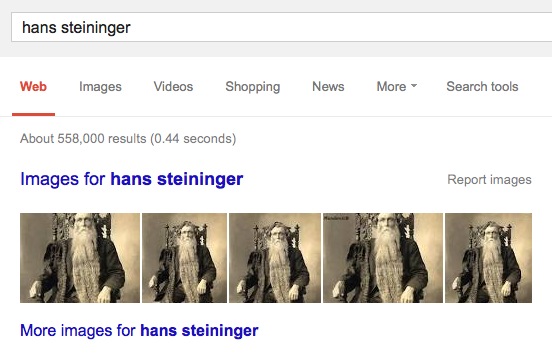
This man is Hans Langseth. I know this because I was a kid who read the Guinness Book of World’s Records a lot and I recognized him from other pictures. He has the longest beard in the world. The image on the right is a clever photoshop. However, if you Google Image search Hans Steininger, you will also find many versions of this photo. This is curious because Hans Steininger (another hirsute gentleman) died in 1567, pre-photography. His beard was also about four feet long whereas Langseth’s beard was more like 18+ feet long.
What happened? Many websites have written little lulzy clickbait articles about Steininger (sourcing other articles that themselves source actual articles at reputable-ish places like Time magazine which are inaccessible because of paywalls) and how he supposedly ironically died tripping over his own beard. They all link to the image of Langseth and don’t really mention the guy in the photograph is a different guy. The image and the name get hand-wavily semantically linked and search engines can’t really do a reality check and say “Hey, we use this image for a different guy” or “Hey, we can’t have a photograph of this guy because he lived in the 1500s”
Not a huge deal, the world isn’t ending, I don’t think the heirs of Langseth are up in arms about this. However as more and more people just presume the search engine and the “hive mind” approach to this sort of thing results in the correct answer, it’s good to have handy counterexamples to explain why we still need human eyeballs even as “everything” is on the web.

Karen Coyle has done an excellent write up of this so I will refer you there.
The full impact of this ruling is impossible (for me) to predict, but there are many among us who are breathing a great sigh of relief today. This opens the door for us to rethink digital scholarship based on materials produced before information was in digital form.
Folks can read the actual ruling (pdf) if they’d like. This is a very big deal. Thanks to folks who worked so hard on getting us to this place. I’ll add a few links here as they come in.
Like many library people, I get annoyed when I tell people I can’t find something on their website and they tell me how to search for it. That said, I know there are things I still don’t know about searching and I like learning what they are. Greg Notess’ Search Engine Showdown is always a first stop. I also enjoyed this post–How to Solve Impossible Problems–about Google research scientist Daniel Russell’s presentation to a group of investigative journalists last week. It’s got two great parts
1. The impossible problem which is just a fun sleuthing puzzle about how to identify a randomish photo (though not so random as it turns out, solution explained)
2. Even more tips about Google that I hadn’t known including the public data explorer and using the word “diagram” when looking for schematic type stuff. Makes sense now that you think about it, hadn’t really thought about it much before.
My inbox is full of little library links and it’s a snow day so I’m settling down to read some longer pieces that I’ve felt that I haven’t had time for. James Grimmelmann is a friend and one of the more readable writers talking about technology and law and the muddy areas where they overlap. He’s written a nice essay on search engine neutrality. What it is, why you might care, who is working on it and how attainable a goal it may or may not be. Specifically, what does it really mean to be neutral, and who decides and who legislates? Quite relevant to all information seeking and finding professionals.
Good reading for a snowy weekday: Some Skepticism About Search Neutrality.
Search neutrality gets one thing very right: Search is about user autonomy. A good search engine is more exquisitely sensitive to a user’s interests than any other communications technology. Search helps her find whatever she wants, whatever she needs to live a self-directed life. It turns passive media recipients into active seekers and participants. If search did not exist, then for the sake of human freedom it would be necessary to invent it. Search neutrality properly seeks to make sure that search is living up to its liberating potential.
Having asked the right question—are structural forces thwarting search’s ability to promote user autonomy?—search neutrality advocates give answers concerned with protecting websites rather than users. With disturbing frequency, though, websites are not users’ friends. Sometimes they are, but often, the websites want visitors, and will be willing to do what it takes to grab them.