I’ve been doing a lot of writing in my newsletter lately. You might like to read it but I do still post here from time to time and I keep my talks list and my booklist updated.
This week I had my most popular tweet ever and it was an interesting experience and I thought I’d spend a few words talking about it since we’re wrapping up National Library Week. Ivanka Trump, the POTUS’s daughter and special assistant, made a fairly banal “Go libraries” tweet. This is to be expected from politicians and celebrities, but maybe not so much ones who are involved in an administration actively working to defund IMLS, one of the major federal organizations that helps libraries nationwide. IMLS gets about $200 million annually, less than the cost of one of those mega-bombs. So, you can imagine how well that went down. It’s actually amusing (to me) to read the top replies. Mostly librarians being like “Are you fucking kidding me?” Top reply tweet was from Margaret Howard who, I am assuming, took the brunt of the haters.
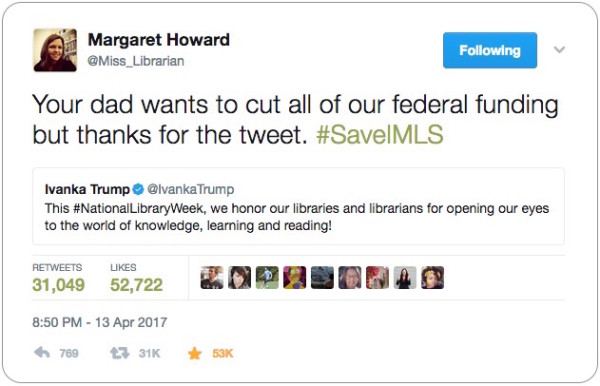
Most of the people replying to or retweeting me were people who agreed and the occasional grump who doesn’t know how to use an Oxford comma. But then someone called me a whore. Which, I have mixed feelings about. I mean, most people don’t like being called a whore. I didn’t take it personally, that person doesn’t know me. I even redacted his personal information before I complained about it, because I didn’t want to turn it into a thing.
However, I did want to see if Twitter’s abuse system was working any better than it has in the past. So before I blocked him, I reported his tweet for abuse. And, unlike in the past, I got an email that said “Hey we received your report and we’ll let you know what happens.” Which, sure, it’s easy to send a “We’re handling this” message. Much easier than it is to handle things. And then today when I woke up, I got a specific email that said his account had been locked and wouldn’t be unlocked until he had agreed to follow twitter’s policies.
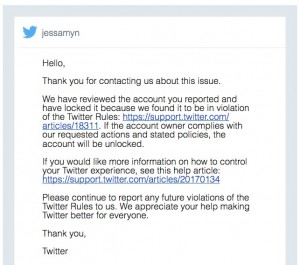
Now I’m not fooling myself I know this probably just involves clicking an “I’m sorry” link and getting right back in the game. I also think my verified status may have helped here, though it’s hard to tell just what the verified status thing really means. I’m also a polite middle-aged white lady who doesn’t lose my shit about this sort of thing which shouldn’t matter and yet might. As I mentioned to someone else, I’m not even sure if the insult was directed at me, there’s a slim chance that the guy was trying to insult Ivanka but that’s still actually not okay. As far as Twitter’s abuse handling, I do feel that this may be too little too late, but I do marvel that it’s even working at all. If you’re someone who deals with harassment on Twitter and gave up on their abuse team long ago, consider trying again, or looking into tools like Block Together which can really help keep the noise down. No one deserves your attention. No one deserves online abuse.