So today my task at the library where I am employed as the nominal “systems” librarian (a very part time job mostly concerned with the eventual automation of the card catalog) was to decipher the procedure for using WebJunction’s TechAtlas (© Powered by OCLC) to do an inventory of our four public access computers. This inventory is mandatory for those applying for funds from the Bill and Melinda Gates Foundation. Here is how my day went.
Our library had gotten a letter from our state librarian including a letter from the TechAtlas people explaining the steps we needed to take to do this. The first step which was strongly suggested but not required was to sign up for a webinar that explained, I suppose, how to do the inventory. My boss wanted to arrange a time where she and I could both be present for the webinar. I got as far as the Wimba set-up asking me to disable my pop-up blocker (do not get me started on the 2.2 MB door card again) and then said I thought we could figure out the process (for our FOUR computers) without it.
The letter had a space where our login and password were provided for us. Unfortunately our letter only had our password and not our login. I called the help number at the bottom of the sheet and talked to a nice lady at NELINET who gave me my login (which was just the password as a techatlas.org email address). She wasn’t sure if it was supposed to be upper or lower case. When I logged in, I had to set up my profile [and choose our own login and password] which included a library name that was not ours. [Note: I fixed this problem, but our “network” still displays a library that is nowhere near us and not related to us]. This occasioned another telephone call to NELINET where they actually had to call the TechAtlas people and get back to me. I had to enter our library’s information — actually my information — on a page with no privacy policy or terms of use. Every time I update an item on my profile page, TechAtlas sends me an email. I have seven emails from them now.
I did track down the privacy policy, not because I’m worried I’ll be spammed but because I think it’s a good idea generally to read them and see what they’re about. Oddly, the privacy policy page in the TechAtlas universe ended prematurely, halfway through the word “statement.” Of course I took a screen capture, but they have since fixed this, making the privacy policy a downloadable pdf, which doesn’t seem super user friendly to me (and hey isn’t that what OCLC just did with another policy…?). Here are the Terms of Service which aren’t in a pdf. There are also the terms of use linked from this About Us page which are a LOT more legalistic. Please keep in mind that if I do not agree with any of these, I am welcome to not use the site and I can not apply for funding in this round of Bill and Melinda Gates Foundation funding.
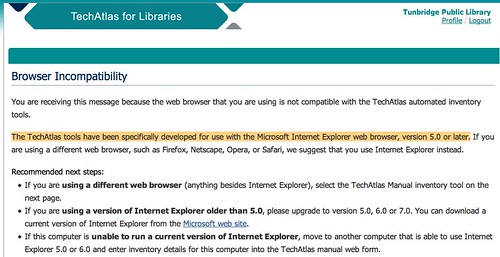
So, on to the mandatory inventory. This was the first thing that greeted me, a browser incompatibility message (some language nsfw there). What this means, in a more polite fashion is that TechAtlas has some nifty IE tools that can make the inventory process a lot simpler. Firefox users need to do more of the process by hand. You know, that’s fine with me. I don’t like it, but that’s okay. However, acting like this isn’t a series of choices that were made by designers and program managers seems somehow odd. Odder still, when I went home this evening to grab some screenshots, the site now gives me a similar “Browser Incompatibility” message and yet displays that I am using a compatible browser. Apparently Firefox got compatible within the last few hours. I guess this is good news? The part they left out is that my browser is incompatible because I’m on a Mac, not because I’m using Firefox.
So we have four computers and it’s not that difficult to fill in the blanks. For each computer, there are twenty-two fields to fill out, but only five of them are mandatory. We have four identical computers so this was actually pretty simple and you can edit the entries if you get anything wrong. Oddly, one of the questions: “Opportunity Online Grant Funds?” which is asking whether you used this certain grant to get the money to buy the computers originally (a question our librarian wasn’t totally sure about, but was pretty sure) isn’t actually editable after the fact. I hope I chose correctly!
So, it didn’t take terribly long. Most of my time at work today was spent cursing at Overdrive and having to do Windows Media Player updates on computers that are locked down via Centurion guard. What I told the librarian — who is a very nice lady, and sympathetic to my muttering in a “There but for the grace of god go I” sort of way — is that this time around, if they let us, maybe we should get Macs.